
What is observability? [Key concepts explained]
Last week, I sent you an article about the cardinality conundrum in observability. That brought up a few questions. The one I didn't expect was, "What is observability, really?" So let's find out...

A simple definition of observability
If I had to explain observability to you for the first time, I’d say it like this:
Observability is a practice that helps us collect, refine and use data on how our software system is behaving. We can query or visualize patterns in the data to solve problems.
You can also call it o11y to save writing observability over and over again.
Why the 11s? Those are the number of characters between the o and y in observability.
I sometimes pronounce it as “Olly” to people who I think would get the context.
My favorite “textbook” 🤓 definition of observability
If I were to make things a little harder and give you a textbook definition of observability, I’d pick this one:
Observability is the measure of a system's ability to allow operators or engineers to understand its internal state and behavior. It involves the collection, analysis, and visualization of relevant telemetry data, such as logs, metrics, traces, and events. This data helps facilitate effective monitoring, debugging, and performance optimization of the software system.
Both definitions give us an idea of what observability can offer, but only one will cut the mustard on Reddit. I’ll let you guess which one.
One other factor is important
Observability is designed to support the real-time nature of needing access to data-based insights. It is also more suited to the nature of cloud-based software.
What kinds of questions can observability answer?
Important ones is going to be my upfront response!
All the effort behind observability is to get solid data to answer critical questions like:
Are there issues affecting users’ ability to complete requests?
How do we NOT fly blind when an outage or security incident occurs?
How can we scale our system to meet changing demand?
Are there any bottlenecks in our system performance and where?
Is our service meeting SLOs?
How do we provide evidence of service uptime in an SLA dispute?
How can we investigate system performance or uptime issues faster?
The big picture of observability
It's a complex area with much to do, a lot of data generated, and a fair risk of messing up.
But it's worth it. Observability not only helps us respond to incidents with the confidence of data.
It supports works that enhance the system. Works like improving other focus areas like system design, release engineering, performance tuning, and more.
SREpath's Island of Observability highlights the big picture of this focus area.
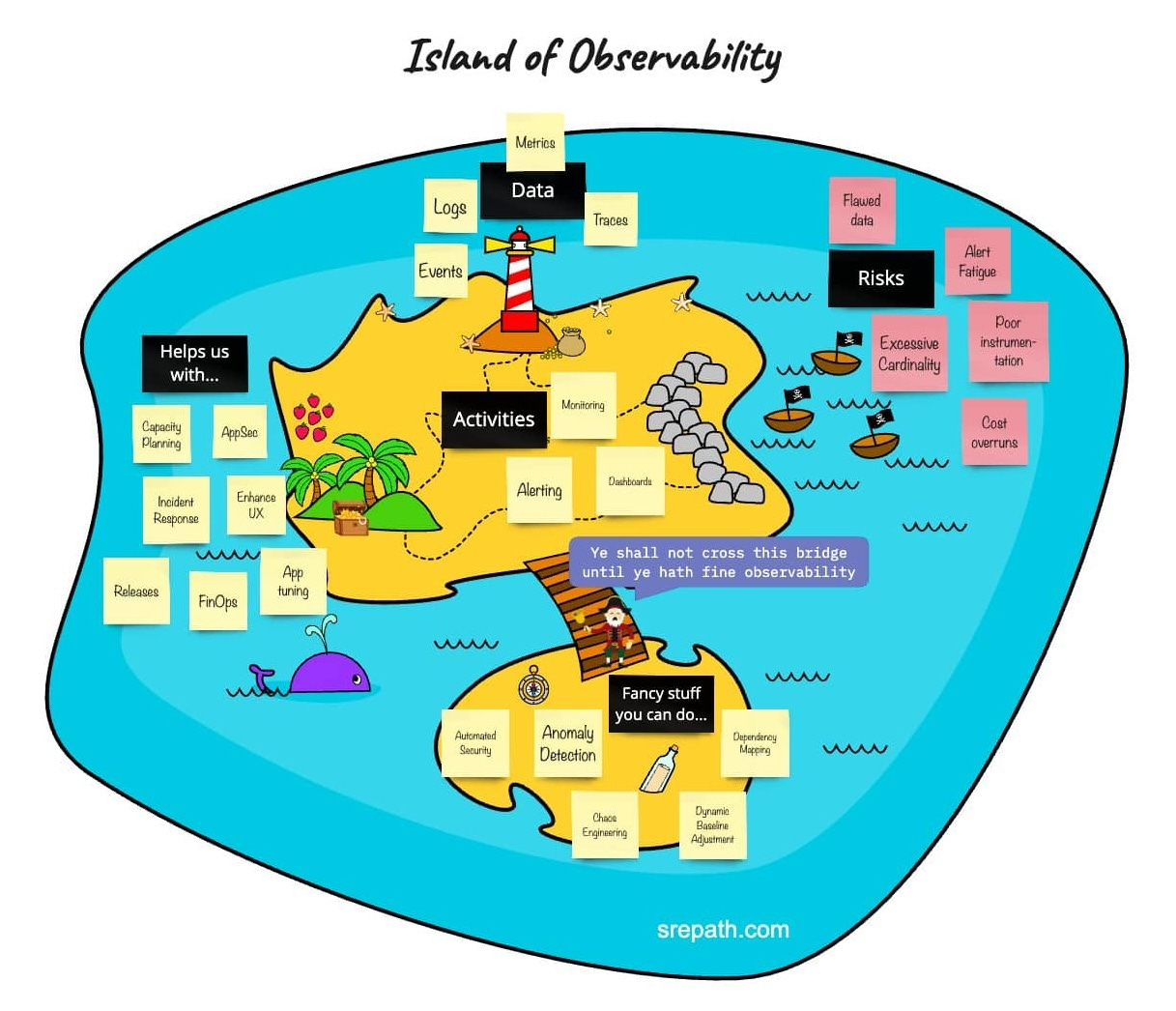
Observability vs monitoring vs APM
I’ve heard a myriad of engineers in different roles mix up the terms just above.
They think monitoring is observability or that their APM tool can fully handle observability.
Nope!
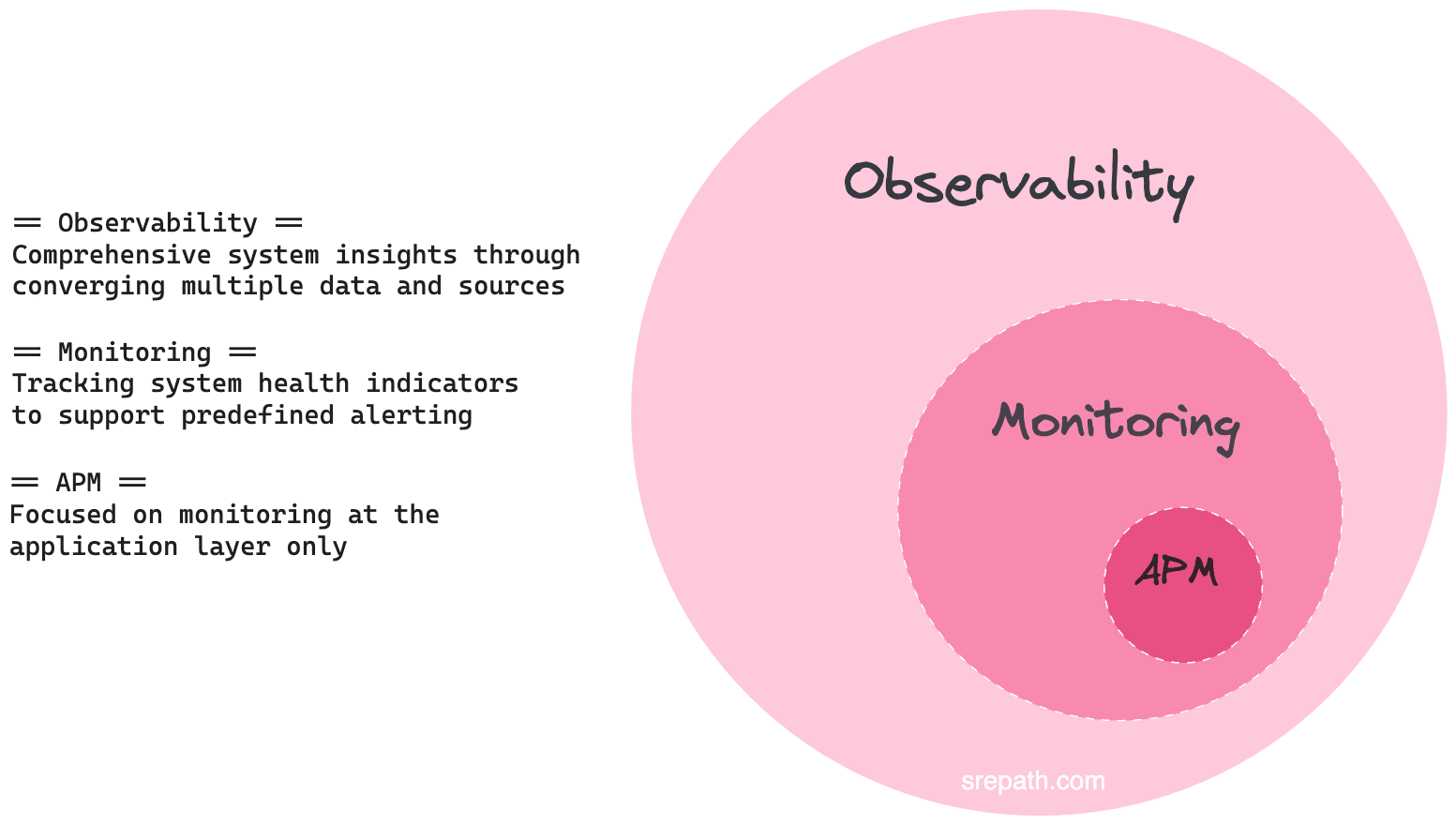
APM and monitoring are older paradigms from simpler times.
They don’t encompass the breadth of observability, but all 3 of these terms are interrelated. We’ll get to that in a moment.
I think it’ll help to define what each paradigm stands for first. Let’s start with APM.
What does APM mean?
APM stands for Application Performance Monitoring. It focuses on the application layer and debugging any problems within applications.
In other words, APM tooling gives you data on how your application performs at a given time. It does not cover other parts of the system like infrastructure or networks.
This model worked well for monolithic architectures where the APM tool was part of the application’s code.
Can you see how this would be problematic to do in cloud-native architecture?
You might have heard of companies like Splunk and New Relic. They started off with APM offerings but are now also focused on observability for the cloud-native reason.
APM is a subset of monitoring, so let’s define monitoring.
What does monitoring mean?
Monitoring within a software system is all about picking up its health data.
Prometheus is an example of a tool solely focused on monitoring.
You can gather data like error rate, traffic levels, latency, and saturation.
I chose this example because latency is my favorite monitoring data — maybe I should have worked as a performance engineer 🤔
By the way, these are known as the ****4 golden signals in the Site Reliability Engineering (2016) book.
Think of monitoring as something that’s always reactive. It’s like a radar that lets you see what’s in your field of view at that point in time.
The key purpose of monitoring for a long time has been to support predefined alerting.
I’ll share an analogy with you in a moment that will highlight this alerting use case, but I need to explain observability again for that. Let me throw a bombshell first…
Monitoring is a part of observability systems, so let’s define observability again now that we are comparing it with others.
What is observability when compared to APM and monitoring?
Unlike APM, observability can collect data from everywhere in the software system. This includes applications, databases, storage, networks, and more.
Observability factors in the complex nature of cloud computing that APM does not.
Unlike monitoring, observability captures data from a proactive standpoint and helps engineers anticipate where issues will arise. It also gives context to alerts when issues occur.
Keep this in mind: APM is a part of monitoring. Monitoring is a part of observability.
Non-software story to highlight observability vs monitoring
Pavan Elthepu gave a brilliant example in the context of a hospital situation.
Imagine a bedbound patient is connected to a heart rate monitor.
The monitor’s heart rate reading suddenly spikes, causing an alarm to sound in the hospital ward.

A nearby doctor rushes to the scene to investigate the issue.
She looks at the monitor and notices the spike in heart rate, but that’s all it can tell her.
What should her next step be to prevent the situation from worsening?
The doctor is well-seasoned and starts looking into medication charts and historical health data.

She finds that the patient had been administered a new pain management drug recently.
Her conclusion is that the drug is causing an increase in heart rate.
The nursing staff then work to administer countering treatments to resolve the issue.
In this situation, the heart rate monitor is analogous to monitoring in that it gathers data to give reactive alerts.
The medication charts and historical health data are analogous to observability data in that they give context to the alert. They helped pinpoint the underlying issue.
You can see from this analogy that observability can be extremely useful for adding context during incidents like outages and security breaches.
What does observability data look like?
You might have heard of logs, metrics, and traces, and events.
These are the main types of data you will find in an observability system.
Each has its use case for helping you investigate and resolve system problems.
Log data definition and example
Logs are recorded messages or events the system generates, providing a chronological record of its activities.
Here’s a simplified example of what logs can look like:
2023-12-01 15:30:45 [INFO] User 123 logged in successfully.
2023-12-01 15:32:10 [ERROR] Database connection timeout.
2023-12-01 15:33:25 [WARNING] Disk space is running low (90% used).
Metrics data definition and example
Metrics are quantitative measures of various aspects of the system and its underlying performance
Here’s a simplified example of what metrics can look like:
cpu_usage_percent: 85
memory_used_mb: 1200
http_requests_total: 1500
error_rate: 0.05
Trace data definition and example
Traces are data that cover the underlying responses within a request as it moves through different components of a distributed system.
It consists of data points known as span, which we explore in another guide that deep dives into logs, traces, and metrics.
Here’s a simplified example of what trace span data can look like:
Trace ID: 12345
Span 1: Service A (Start Time: 15:30:00, Duration: 500ms)
Span 2: Service B (Start Time: 15:30:05, Duration: 300ms)
Span 3: Database Query (Start Time: 15:30:07, Duration: 100ms)
Span 4: Service C (Start Time: 15:30:10, Duration: 200ms)
Span 5: Service D (Start Time: 15:30:12, Duration: 150ms)
Event data definition and example
Event data in observability provides fine-grained details about notable events.
Each event includes a timestamp, event type, contextual information, and a payload.
Events are crucial support data for incident response and root cause analysis.
Here’s a simplified example of what event data can look like:
{
"timestamp": "2023-05-01T12:34:56Z",
"eventType": "UserLogin",
"context": {
"userId": "12345",
"location": "Homepage"
},
"payload": {
"status": "Success",
"ipAddress": "192.168.1.100"
},
"source": "AuthService"
}
Observability data can come from multiple sources
Catchpoint’s 2023 SRE Report found that over 53.5% of its 550+ respondents in the reliability space worked in an environment with 3 or more sources feeding their observability system.

What’s the significance of this finding?
It’s the recognition that having multiple data sources is crucial for obtaining a comprehensive and accurate understanding of the system's dynamics.
The risk of having a single source of truth (that IT vendors love selling) is that you risk missing the complete picture of what’s happening.
What kinds of sources can we get data flowing in from?
Here are 5 examples that are most relevant to software in production:
applications
infrastructure
network
front-end UX monitoring
client-side device monitoring
Imagine having only infrastructure observability data and no information about how applications behave. Such a scenario would mean doing guesswork to pinpoint issues.
This is why it’s best to cover infrastructure and applications at a minimum.
Where is all this observability data going?
Observability data follows a journey to usefulness

⚠️ The shape of the arrows means something. I’ll explain after we go through the flow process.
Let’s do a simplified rundown of what happens at each stage:
Instrumentation
You insert monitoring code (listeners) into the services you want to collect metrics from
This code gathers data about the service's performance, errors, etc
Examples of tooling at this stage include Prometheus, OpenTelemetry
ℹ️ A quick aside on OpenTelemetry. CNCF is the open-source cloud computing tooling network, and OpenTelemetry is the second most contributed project there. Its purpose is to make instrumenting your code for data collection painless.
Ingestion
The listener code then sends collected metrics data to a data collection service
These are often called collectors. These collectors organize and process the incoming data
Examples of tooling at this stage include Prometheus, Kafka, FluentD
Storage
The metrics data then gets pushed to designated databases for storage
These databases are often designed to store time-series data, common in monitoring and observability systems
Examples of tooling at this stage include Prometheus, OpenTSDB, InfluxDB
Usage
This is the final stage and where you can use the data for several purposes
You can use it for alerting, creating dashboards, and supporting machine querying
This helps you stay on top of system behavior, performance, and issues
As I mentioned under the last image, data flow issues can happen in observability.
I will cover them more in-depth in an upcoming guide called How to Solve Poor Data Flow in Observability.
How is observability data stored?
Most modern observability tools work with time series databases (TSDBs).
These databases help us understand what a metric is up to at specific moments in time.
You might catch Comp Sci PhDs calling these time series a "temporal aspect."
Components of a time-series database (TSDB)
In a TSDB, time series data is organized into individual series.
Definition: we are ordering a sequence of data points in terms of time. Hence time series.
Each data point usually has a timestamp and corresponding value/s.
Here’s an example of what time series data looks like:
Metric Name Dimensions (labels) Timestamp Value http_requests_total {status=”200”, method=”GET”} 2023-11-24 09:00:00 1010 http_requests_total {status=”404”, method=”GET”} 2023-11-24 09:00:00 239 http_requests_total {status=”200”, method=”GET”} 2023-11-24 09:00:01 1028 http_requests_total {status=”500”, method=”GET”} 2023-11-24 09:00:02 10383
The above example captures what time series data could have looked like for some eCommerce sites at the beginning of the Black Friday sale on November 24th, 2023.
Let’s break it down:
At exactly 9 am, they had 1010 successful “200 OK” requests and 239 unsuccessful “Page not found” 404 requests.
A second later, they had 1028 successful “200 OK requests”
But only a second after that, they had 10383 requests that got a “500 internal server error” response — possibly due to more requests than server capabilities
Series? Huh?
Think of a series like this. It is the unique combination of a metric name (what you are trying to gather) and the key-value pairs that make it up.
The cherry on top is a timestamp that marks: “This is what happened at this point.”
That’s why it’s called a time-series database 😉
You can also see adding each new key-value pair as adding a dimension.
You will hear these terms being used in observability conversations a lot:
Don’t add a new dimension to your series unless you know its cardinality is worth it.
You can explore the important concept of cardinality here.
Let’s break down a series
Remember it has the metric name and the key:values that compose it.
Here’s a common example of a metric name:
http_request_duration_seconds
Dimensions can include:
method(e.g., GET, POST)status_code(e.g., 200, 404, 500)endpoint(e.g., /api/v1/resource)server(e.g., server-1, server-2)
Every series will give a response on a new line like:
http_request_duration_seconds{method="GET", status_code="200", endpoint="/api/v1/resource", server="server-1"}Duration: 0.235 seconds
http_request_duration_seconds{method="POST", status_code="404", endpoint="/api/v1/user", server="server-2"}Duration: 0.540 seconds
http_request_duration_seconds{method="GET", status_code="500", endpoint="/api/v1/resource", server="server-3"}Duration: 1.120 seconds
How is observability data being used?
It’s going places, don’t you worry about that. I mean real practical uses.
We are ingesting, storing, and then querying it for 3 purposes:
Alerting — helps us respond to outages and other incidents
Dashboards — gives SREs and other rockstars a big-picture view of system health
Intelligence — machine learning pulls data to analyze for predicting trends and proactive work
How does observability add value to software operations?
As I mentioned earlier, observability is often used as a conduit to doing other software operations activities better. It can help with:
Incident response — Observability provides real-time insights into system behavior, which helps minimize the impact of incidents through rapid identification and resolution of issues
Improving system design — System architects and engineers can gain a deep understanding of system internals to enhance its design by analyzing observability data
Capacity planning — Capacity planners like SREs can use observability data to see trends in resource usage to make informed decisions for scaling systems up or down
Assuring smooth releases. Observability can help identify and cut the risk of potential issues that can cause post-release incidents, resulting in smoother software deployments.
Performance tuning — Observability data can help pinpoint system bottlenecks and inefficiencies that performance engineers and SREs can use to optimize components
What are some risks in observability practice?
I mentioned several data flow issues earlier, but many of these can be kept in check by staying on top of the constant upgrades in observability tooling.
Some other issues can be on top of mind in observability.
The most critical one I’ve encountered is the high cardinality issue.
I wrote a full guide on the cardinality conundrum to give you a view of what it means.
The high cost of observability systems (some reaching 7-figure costs) is also a bugbear for many software-dependent organizations.
Data quality issues can also come and can be directly related to the flow issues I mentioned earlier, but sometimes they’re a beast of their own.
And finally, the one I’ve been asked about more than once is alert fatigue. Poorly configured alerting can cause burnout in engineers from excessive cognitive load.
Whether it’s purely an observability-related issue is up for debate. I’ll leave it here.
Wrapping up
Observability is not as straightforward as it may be marketed to be.
There are a lot of nuances in making it work well and using the data to its full potential.
Keep the data flowing well, and it will serve your reliability work just as well.