
Intro to logs, metrics, and tracing
This introductory guide is a deeper look into logs, metrics, and traces than what’s inside the What is Observability? guide.

Logs, metrics, and traces are considered the 3 golden pillars of observability.
I’d say they are the minimum you need for effective observability.
There are a lot more signals you can pick up from your systems, but these 3 are the core ones you should master before you move on to others.
Logs
What are logs?
Logs are text-based records of events and messages that your software system emits.
Why would I use logs?
Logs are an important activity in developing software.
Debugging software is much harder without knowing what kind of error messages your software is producing.
You can also create automated alerts to trigger when a specific log level e.g. WARN or ERROR occurs.
More modern logging systems can even support your efforts to collect metrics and traces, which we’ll get to later.
What kinds of logs exist?
Here are some examples:

What is found in a log?

You will typically find the following elements in a log:
Timestamp — the time the event or message occurred
Source identifier — this could be your microservice’s name or instance ID
Levels — helps you know the importance of a record e.g. INFO, DEBUG, WARN, ERROR, etc.
Description — gives further details of the event or message
What do the various log levels mean?
INFO means you are getting details about the normal functioning of your app or system
DEBUG can help developers trace an execution flow for troubleshooting purposes
WARN will indicate that something is starting to go wrong or deviate from normal
ERROR will indicate that there is some kind of issue or failure related to the source
How is log data structured?
Log data for most of its existence has been unstructured data stored in plain text files.
Here’s an example of unstructured log data:
2022-01-08 15:30:00 | Error | Application crashed
2022-01-08 15:35:20 | Info | User logged in
2022-01-08 15:40:45 | Warning | Disk space low
Now, the modern way is JSON to represent log data.
Here’s an example of JSON-based log data:
[
{
"timestamp": "2023-01-08T15:30:00",
"level": "Error",
"message": "Database overload!"
},
{
"timestamp": "2023-01-08T15:35:20",
"level": "Info",
"message": "User logged out"
},
{
"timestamp": "2023-01-08T15:40:45",
"level": "Warning",
"message": "Disk space approaching 90%"
}
]
How do you gather logs on your systems?
A lot of popular frameworks like Ruby, Python, and Javascript come with their own logging libraries, so be sure to check them out.
You can also add logging functionality through external frameworks like Log4j (for Java).
OpenTelemetry also has SDKs to instrument for logging in several popular languages.
3 golden rules for maintaining your logs

Let’s unpack each of these a little further:
Rule 1: Push all logs into a central repo
Life was simpler when monoliths were around. You could get all of its log data in one place.
But it’s no longer so simple, now that most software systems have distributed components like VMs, databases, and more.
A fragmented view of the system’s performance is one of the biggest risks from log data being held near each of these components.
It also increases the complexity of solving log issues like storage and security.
Log aggregation can help push all the fragmented log data into a centralized repository.
This can drastically simplify storage and management of logs.
Rule 2: Stay on top of log storage
The simple aspect of this rule is the more log data you store, the harder it gets to manage them.
Logs can come with an operational overhead in terms of capacity planning work, storage costs, and complexity.
I know of companies that are spending high 6-figures every month to store their log data when they could cut those costs down to low 5-figures by applying good techniques.
Techniques like:
Log compression — reducing the log data size using compression algorithms
Log retention policies — having a set policy for when log entries should get purged ensures ongoing control of log data size
Automated log file reduction — automatically trim older log entries at certain time intervals or file size limits
Rule 3: Keep your logs secure
Logs can contain sensitive information like error and warning messages that can tell bad actors about your system’s architecture and its inner (non)workings.
They can work out the breadth of your system and where they can find the weakest spots to infiltrate with measures like brute force attacks, evasion-based testing, and more.
You can apply some of these methods to reduce your logs’ security risk:
Sanitize logs regularly — clean up any sensitive information e.g. user input or tokens from logs once it's a second past its usefulness for debugging and incident handling
Restrict your logging levels — sensitive levels like DEBUG (which can link to a vulnerability) should have restricted access
Regular audits of logs — check your logs to make sure that sensitive information is not staying on long-term and that access is restricted
Log data lifecycle

3 ways to make analyzing log data easier
Logs are a firehose of data since they collect it from all kinds of components in your system.
You need to use a few analysis techniques to make sure you get good value out of them. Techniques like:
Search and filtering
Helps you sift through the big data of logs fast by finding or filtering down to log entries with keywords, time ranges, or levels
Tools that can help include Elasticsearch, Splunk, or ELK
As an example, you could use this ability to find entries with the type ERROR throughout the system so that you can track issues faster
Parsing
This is very useful if you haven’t got JSON-based logs and your data is unstructured
You can break log data into meaningful attributes to extract valuable insights
Of course, you can always turn your logs into JSON to make it easier to process
Trend analysis
You will benefit most from your log data when you can identify patterns and trends within
One of the easier ways to do this is to visualize the data on dashboards and graphs
You can then see how key numbers like ERROR levels are moving and more
Metrics
What are metrics?
Metrics are measurements that give you an indication of how a certain aspect of your software system is doing or performing.
They are always number-based i.e. quantitative measurements.
Why do I need metrics?
Metrics are important data for your software system.
They can help guide your decision-making as to how to improve your system.
You can use metrics to guide capacity planning efforts which is a big part of Site Reliability Engineering (SRE) work.
They also come in very handy during incident response to see where issues are occurring, which once again is a huge part of SRE work.
They are the main data contributor to alerts.
What kind of metrics exist?
Here are some examples of metrics:

You can develop and consume metrics for:
applications
infrastructure
networks and other system components
You will encounter 4 types of measures when it comes to metrics:
Counters — measure the number of times a particular action or event occurs e.g. http_requests_total gives a count of the number of HTTP requests
Gauges — provide a snapshot of the current level of a metric at a particular time e.g. memory usage_mb gives a measurement of memory usage at a particular time
Timers — measure the duration or latency of an event or process e.g. request_duration measures the length of time it takes to initiate and complete a request
Histograms — provide a distribution of values broken down into buckets or set intervals e.g. response_time_histogram shows the breakdown of times falling into 0ms, 10ms, 20ms, etc
What is found in a metric?
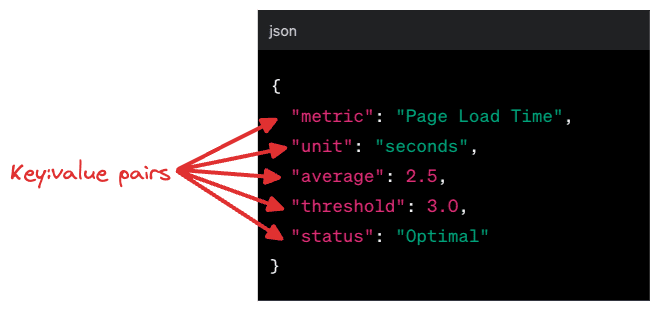
You will find that metrics are composed of various key:value pairs like above.
The example above shows a metric called “Page Load Time” that is measured in seconds with the average being 2.5 seconds and an acceptable limit of 3 seconds. Because the average is well below 3 seconds, the status is considered optimal.
You will rarely see a simple metric like this in your system, but I wanted to keep it simple to explain the breakdown of a metric to you.
You will more likely see metrics like this:
{
"metric_name": "http_requests",
"region": "us-east",
"http_method": "GET",
"status_code": 200,
"response_time": 25.3,
"bucket": "low",
"timestamp": 1642267200
}
How do you gather metrics from your system?
You can use various open-source and commercial tools for gathering metrics.
Open-source options include Prometheus, Grafana, and more.
You can also use commercial tools like Datadog and New Relic.
OpenTelemetry once again has stable SDKs to instrument for metrics in several popular languages. You can read an intro guide to OpenTelemetry here.
3 golden rules for building your metrics

Let’s unpack each of these a little further:
Rule 1: Define your metrics clearly
Your metrics should fit a very specific purpose that supports you in solving a problem, known incident type, or business need.
A metric can consist of multiple key:value pairs that relate to a specific aspect of the metric.
You can precisely define your metrics by stating your key:value pairs as:
what is being measured e.g. latency
how it’s calculated e.g. time elapsed from start to end of request and
the unit of measurement e.g. milliseconds
A metric can get complicated fast with a rise in key:value pairs.
Pay special attention to the cardinality of each key:value pair.
High cardinality key:value pairs like user IDs can cause a surge in data leading to storage issues.
Rule 2: Establish baselines and thresholds
It’s all well and good to define what data you want to collect, but a lot of the time you want the system to tell you if a metric is not getting optimal results.
You can do this by establishing baselines and thresholds.
Your baseline number outlines your comfort level for the specific measurement.
Thresholds set the level where you start getting red flags about the metric you’re collecting.
Let’s look at the metric example below:
{
"metric_name": "http_requests",
"region": "us-east",
"http_method": "GET",
"status_code": 200,
"response_time": 25.3,
"timestamp": 1642267200,
"baseline": {
"average_response_time": 20,
"acceptable_status_codes": [200, 201, 204]
},
"threshold": {
"response_time": 30,
"error_rate": 5
}
}
Your baseline has an average response time of 20ms.
We’ve also added status codes within the 2xx range that signify successful requests.
Now, let's talk thresholds.
If we see the response time going beyond 30ms, that's a signal that something might be off.
But that's not all – if this happens and we notice error codes repeating more than 5 times, it's a double whammy, and we consider it a problem.
Now you might be thinking: why can’t I just set thresholds in my alerting tool or monitoring system? You can, and that’s what a lot of people do.
But setting the threshold within the metric itself protects it from multiple individuals setting different alerts over time for the same metric. That can reduce alert fatigue risk.
Rule 3: Know the context of your metrics
Context is your secret decoder ring.
It turns raw data into meaningful insights.
Not having the right context means you might think your site is crashing. But in reality, it's just handling the Black Friday rush like a champ.
When you have context, you can distinguish normal behavior from the unusual.
You can look into the context in terms of:
Day or time
Special events
Typical user behavior
Metrics data lifecycle

How metrics are consumed
Alerting
By far the most critical use of metrics
These help identify when system and application issues are occurring in real-time
They continuously assess values and trigger when thresholds are hit
Dashboards
One of the most common ways metrics are consumed
They can provide real-time and historical views of metrics through charts, counts, and graphs
You can use this to help resolve chronic or wide-spanning issues
Machine learning and data analysis
One of the more promising uses of metrics data
Can analyze and uncover hidden patterns and predict trends — without human intervention
Helps you get deeper insights into system behavior than your manual analysis work
There are a lot more areas that use metrics data, but the above 3 can take most engineers very far in their work.
Tracing
What are traces?
Traces are like detailed records that show every step a request or process takes in your system, helping you understand and fix any issues.
In essence you are understanding the lifecycle of a request or process.
Why would I use traces?
Traces can help you find bottlenecks within a particular process or request chain.
By nature, request chains can have multiple requests within. That can make it very hard to pinpoint where the error is occurring.
Tracing breaks the chain down to work out how each individual request is performing as it initiates and hands off to the next request.
This makes it a lot easier to work out where in the request chain you are experiencing excessive latency, for example.
It could mean finding the issue with a database that forms a critical step in a request.
In another situation, it could be a particular piece of code thats causing trouble.
What kind of traces exist?
You can find traces in two forms, but one can fit inside the other.
You can trace internally within a service e.g. within a backend service.
You can trace across multiple services e.g. from frontend to backend to database and back.
The latter is known as distributed tracing and is the more common way to run tracing.
What is found in a trace

Original image via jaegertracing.io
The core element of tracing is spans.
Spans are called the “unit of work” within a trace. They measure the duration of an activity i.e. how long it takes a particular action to start and complete.
In most situations, a span is measured in milliseconds. Each span comes with a span ID to make it easy to deepdive into later on.
Spans can be children of other spans. In the above example, the various spans under Inventory are children of the Inventory span above them.
How do you gather tracing data from your system?
Open-source options include Jaeger and Zipkin.
Tracing is an area that OpenTelemetry excels in since it incorporates the very mature OpenTracing framework.
You should be able to find stable SDKs to instrument for tracing in several popular languages.
3 golden rules for managing your tracing

Let’s unpack each of these a little further:
Rule 1: Define your tracing context
This means you need to set unique identifiers and propagate them consistently across your request. You need these to be clear with your spans.
You can’t link spans together without this work, which makes it hard to get full visibility into a particular request.
So to do this right and define the context:
Set a unique trace ID for each incoming request
Give each component within the request a unique span ID
Propagate these identifiers by including them in headers or context objects
Rule 2: Instrument thoughtfully
Tools like OpenTelemetry make it easy for you to instrument everything for tracing, but that doesn’t mean you should.
You want to gain meaningful insights from important requests.
You don’t want to overwhelm your system with excessive data.
So how do you instrument thoughtfully? Here’s how:
Work out what services and components are critical to knowing your system’s behavior
Instrument only the ones that will help you understand:
system performance
diagnosing bottlenecks or
improving latency
Avoid the temptation to instrument every component to prevent noisy tracing data
Rule 3: Correlate traces with logs & metrics
One of the most important aspects of observability is that it integrates multiple data types to give you a bigger, stronger picture of the system.
Doing so can help you identify root causes more effectively and often faster.
Not doing so means tracing data is own its own when really, it could benefit from log data to support its context.
So how do you make this integration happen? Here’s how:
Ensure that logs include trace IDs
Be consistent with how you tag components and services so you can link up their traces, logs, and metrics
Leverage tracing and logging libraries that integrate with observability platforms
How logs, metrics and traces work in unison
Picture logs, metrics, and traces as the dynamic trio in the backstage of your software.
There are a bunch of other signals, but these 3 are the core foundation of your observability work.
Logs keep a record of every event, significant or not.
Metrics help you keep a scorecard on system health.
Traces map out the journey of each request from start to finish.
Bringing these three together is like weaving a compelling story — traces connect the dots, metrics add the numbers, and logs provide the backstage commentary.
It's your backstage pass to understanding and fine-tuning your system.
This trio has your back when you need to work out, “What’s going wrong here?”
They are your ticket to more visibility during troubleshooting and improvement work.