
How to Solve 3 Data Flow Issues in Observability
Going into an incident, the last thing you want is an incomplete picture of what’s going on under the hood. That’s what can happen when you have observability data flow issues.


The scary thing is — it’s really easy to fall into this situation.
We’ll first explore how data flow issues manifest in observability.
We’ll then look at the specific problems in data flow.
And finally, we’ll work through a few potential solutions.
Sound good? Let’s get started.
Unpacking poor data flow
In plain English, you risk not getting enough data.
It’s like trying to fill a swimming pool with water using leaky or clogged piping.
In this scenario:
the swimming pool is your observability data lake
the water is observability data and
the clogged piping is your observability data pipeline.
With leaky piping, the data you need might not be coming through properly to fill the pool.

End result and risk: your big observability data pool isn’t as full as it should be, leaving you with an incomplete picture.
Before we dive into specific issues, let’s do a refresher on how observability data flows…
Refresher on data flow in observability
I mentioned in the guide Key Observability Concepts Explained that observability data flows through 4 stages. It flows like so:

I also mentioned in that guide that the arrows have meaning to them.
They denote how easy (or not) the flow is from one stage to the next.
Let’s explore these flow relationships:
Instrumentation ⇒ Ingestion
This stage is when the data goes from instrumented code and components via collectors to ingestion at the central observability system.
It should be straightforward but can get a little tricky if you have a large variety of data sources, poorly formatted data, or real-time requirements
Ingestion ⇒ Storage
This stage is less tricky as the data is already in a format that databases like and simply needs to flow into storage.
But you can get issues here when there is a large volume of data to push or data coming in at high velocity.
Storage ⇒ Usage
You can expect a myriad of issues at this stage because data retrieval can be a pain.
Query complexity can make time-to-usability slower than you’d like. On top of that, visualizations need intensive processing power.
<aside> ℹ️ Data flow is not the only observability data issue. Check out this guide on the other major issue afflicting **observability data: data quality.
</aside>
This is a high-level view of how the data flows and some kinks that can slow things down.
But there are more serious issues that can plague data flow.
Let’s explore them now…
What are the 3 main data flow issues?
We can put data flow issues into 3 buckets:
Siloed Data
Latency & Delays
Incomplete Data

We’ll explore each of these buckets in detail in a moment.
Before we do that, let me explain the star rating system I will use later on to guide you through the tasks inside each bucket.
I will rate each task with the following on a 5-star (★★★★★) scale:
ease of doing — how easy would it be to implement and keep doing
cost — factoring in engineer time and potential vendor costs
impact — what level of difference it can make to data flow in observability systems
(Spoiler alert: nothing gets 5 stars for impact because that is reserved for tasks with exceptionally high or transformative impact)
My ratings are based on the assumptions that:
the work will get assigned to SREs with at least 1-3 years of experience
the team aims to get open-source tooling rather than pay vendors from Day 1 and
that observability is considered pivotal to providing system insights
For each of the 3 issue types, I’ll give a quick overview then break down the associated tasks.
Let’s begin!
Overview of incomplete data
This implies that your observability data has gaps. The magnitude depends on the number of issues that are plaguing it. By issues, I mean:
technical errors
misconfigurations and
infrastructure limitations
How to reduce incomplete observability data
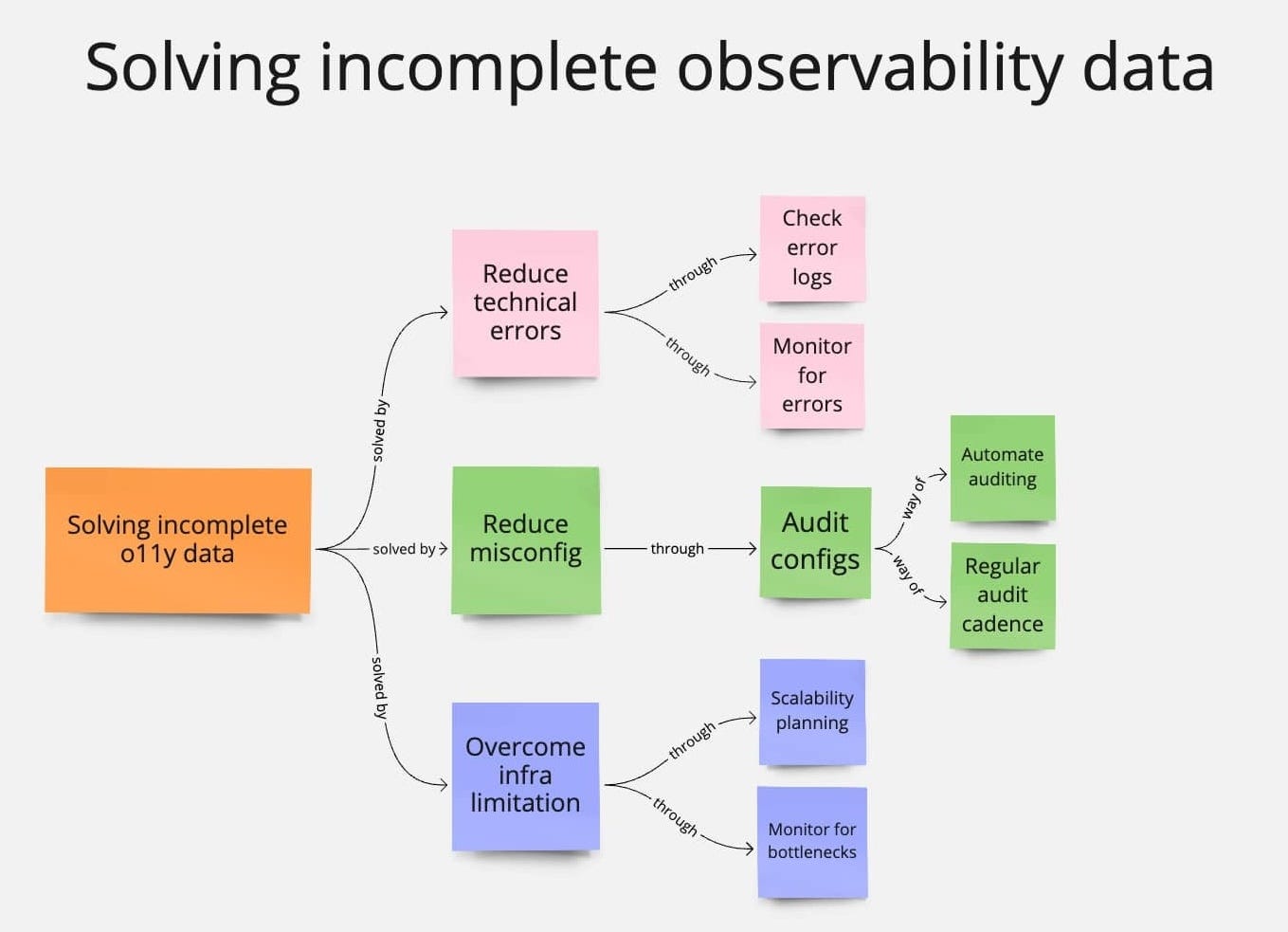
Summary concept map for solving incomplete observability data issues
Let’s look into 6 ways you can resolve the above 3 issues:
Reduce technical errors
Check your error logs
Step 1 is having a robust error logging process in the first place. You should then have a simple mechanism for checking errors, exceptions, and failures.
Ease of Doing ★★★★☆
Setting up a robust error-logging process is manageable, and checking errors is relatively easy but consistently doing so requires manual effort
Cost: ★★☆☆☆
The cost of setting up error logging is reasonable. Manual checks incur some operational overhead but don’t take up excessive time
Impact: ★★★★☆
Regular checking of error logs has a high impact on identifying and resolving issues promptly, providing valuable insights into system health
Monitor for errors
Implement monitoring tools to track and alert when technical errors occur in the collection stage. This helps in the real-time identification of issues.
Ease of Doing ★★★★☆
Monitoring tools involve some setup and configuration, which can be straightforward but only if you’re already familiar with monitoring tools. making it moderately straightforward. This process requires familiarity with monitoring tools.
Cost: ★★★☆☆
Monitoring tools may come with vendor costs, but the investment is justifiable because it helps with real-time insights needed to assure reliability
Impact: ★★★★☆
Real-time identification of errors has a high impact on system reliability, enabling proactive issue resolution and minimizing downtime.
Reduce misconfigurations
Audit configurations.
Set a regular cadence to check if your system is configured correctly.
Ease of Doing: ★★★★☆
After the initial troubleshooting and training period, conducting regular audits of configurations becomes more straightforward
Cost: ★★☆☆☆
The cost of manual audits is low to moderate in most situations — so long as your Director of SRE doesn’t get involved
Impact: ★★★☆☆
Regular audits are like the annual health checkup that help maintain system reliability
Automated audits.
Ease of Doing: ★★★☆☆
Automated audits may require some scripting and/or integration work — you gotta code it, so it takes a moderate level of effort for an SRE with coding skills
Cost: ★★★☆☆
Automation tools come with costs from engineering time, but the efficiency gained in automated checks justifies the investment
Impact: ★★★★☆
Automated audits enhance efficiency by proactively identifying and resolving misconfigurations, contributing to system stability
Overcome infrastructure limitations
Monitor for bottlenecks.
Use performance monitoring on the observability system itself to find where the bottlenecks are
Ease of Doing: ★★★★☆
SREs are adept at running performance monitoring tools and addressing bottlenecks
Cost: ★★★☆☆
The cost of performance monitoring tools varies and the time taken to implement and support them too but it’s worth the impact
Impact: ★★★★☆
Getting rid of bottlenecks can have a high impact on data flow
Scalability planning.
Scale the observability infrastructure to handle the increase in data volume if it is showing consistent patterns
Ease of Doing: ★★★☆☆
SREs with at least 1-2 years of experience should be familiar with capacity planning and system dynamics that govern it
Cost: ★★★★☆
The cost of scalability planning involves strategic investment in infrastructure to handle increased data volumes
Impact: ★★★★☆
Proper scalability planning means the system will be able to handle increased observability data volumes
A few notes:
With all of the above tasks, you are mitigating a problem that has already occurred
The order in which you tackle the tasks depends on the problems you find in your observability system’s data flow
It’s not easy to prevent any of these except perhaps persistent infrastructure scaling issues through autoscaling (super tricky work)
That’s why you should remain vigilant of errors and misconfigurations in the observability system
Overview of latency and delays
You’ll find that one of the most useful aspects of modern observability systems is that they can give us real-time insights.
But this implies your data pipeline is capable of pushing real-time data through all stages in a timely fashion. Latency and delays in data flow will hinder this.
But the good news is that latency and delay issues can be prevented with good practices, which we will cover now:
How to reduce latency & delay issues
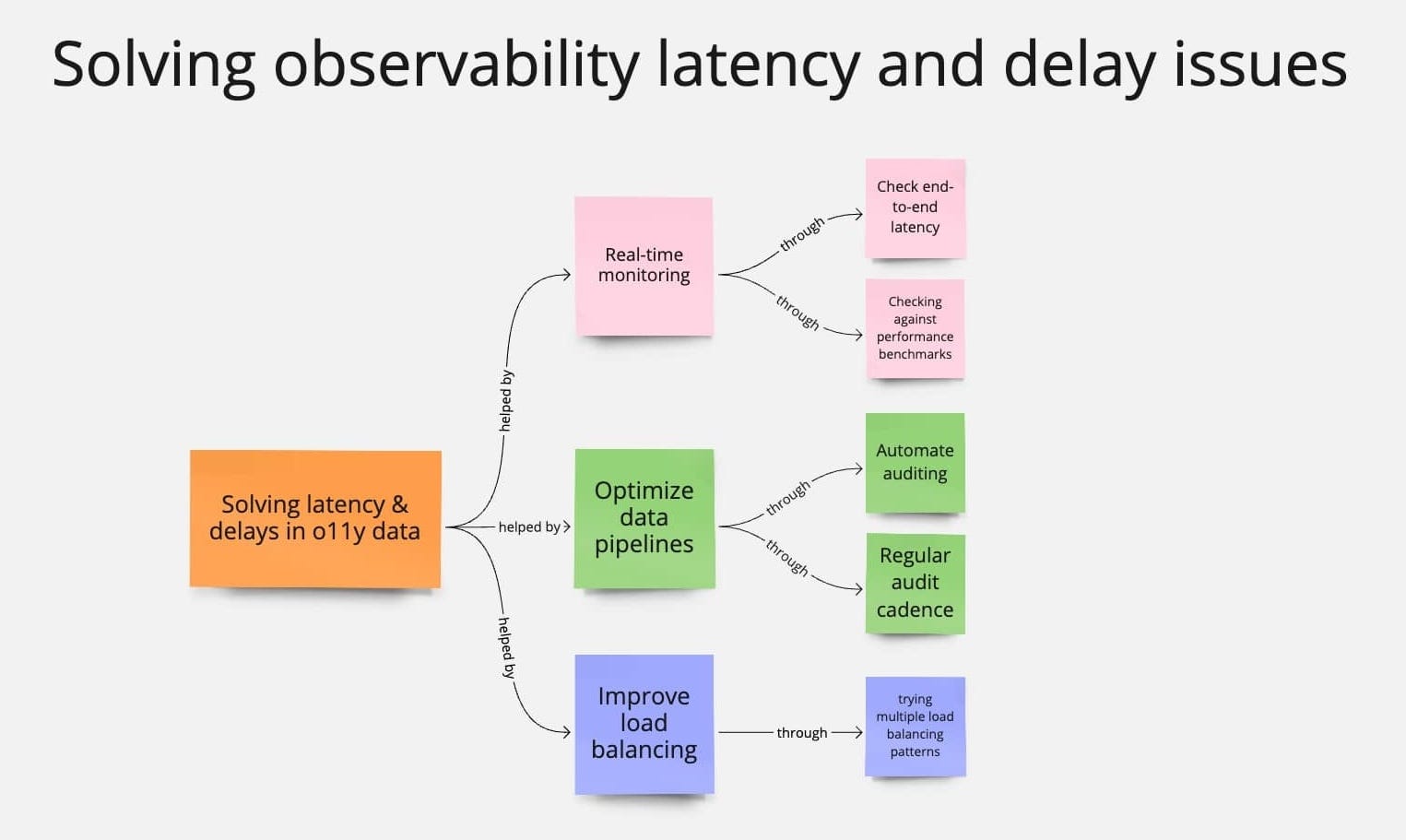
Summary concept map for solving observability latency and delay issues
We are trying to improve the timeliness of data and minimize bottlenecks. To do that, we can:
Implement real-time monitoring.
Not for your software, but the observability system itself to see how its data flow is performing at various points
Ease of Doing: ★★★★☆
Real-time monitoring for the observability system’s data flow itself is generally achievable with modern monitoring tools
Cost: ★★★☆☆
Explainer: The cost is moderate because it involves vendor costs and the possibility of needing additional infrastructure
Impact: ★★★★☆
Real-time monitoring significantly boosts the observability system's ability to detect issues promptly for swift resolution
Improve load balancing.
Implement load-balancing strategies including not limited to:
Weighted round-robin balancing — distribute more requests to nodes weighted to have more processing capacity
Least connections balancing — route requests to nodes with the least active connections at a given time
Geographic load balancing — route requests to the nearest node to minimize latency
Ease of Doing: ★★★☆☆
SREs usually stay on top of a few load-balancing strategies for actual application workloads, but it can take time to review the observability system architecture
Cost: ★★★☆☆
Costs are mainly associated with engineering time to set up load-balancing configurations but might also include commercial load-balancing tools
Impact: ★★★★☆
Improving load balancing has a significant impact on system performance through more efficient distribution of requests, lower latency, and less overloads
Optimize data pipelines.
Set a regular cadence to review and enhance data processing pipelines to reduce bottlenecks and streamline processes
Ease of Doing: ★★☆☆☆
Optimizing data pipelines requires a systematic approach to reviewing data processing stages and making adjustments to configurations and workflows
Cost: ★★★☆☆
The cost is moderate because it mainly involves engineer time for the initial review work and then periodic reviews and enhancements
Impact: ★★★★☆
Optimizing data pipelines has a significant impact on reducing pipeline bottlenecks
Overview of siloed data
Observability systems pull data from multiple sources including applications, infrastructure, networks, and more.
Because all of these components are separate, there’s a risk that all your observability data can end up sitting in siloes next to each component.

This defeats the whole purpose of observability systems which are supposed to bring together data from multiple disparate sources to give you a big picture.
Lord help you if you have to solve this problem because doing so almost turns you into a data engineer! Almost…
How to prevent siloed data
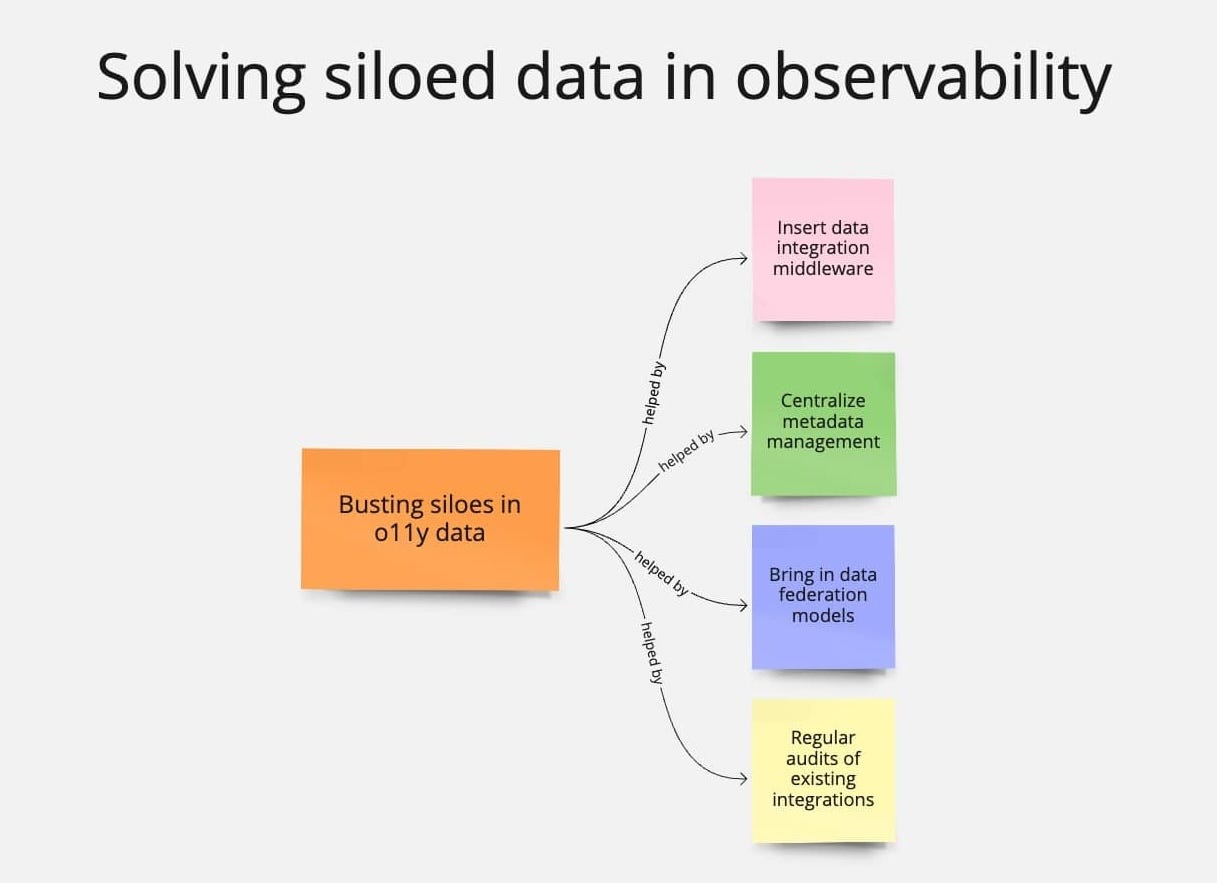
Summary concept map for busting siloes in observability data
Siloed data requires bringing in data tools and techniques to unite data. You may need to:
Regularly audit existing integrations.
Define policies that guide the data your system should generate and then regularly check against them.
Ease of Doing: ★★★★☆
Regularly auditing existing integrations is straightforward once you have properly defined your policies
Cost: ★★★☆☆
The cost is mainly engineer time in doing the initial integration inspections, creating the policy, and then the ongoing checks
Impact: ★★★☆☆
Regular audits are a simpler and moderate impact way to solve data flow issues stemming from integration issues
Centralize metadata management.
Metadata can be useful for identifying various sources of data to pull into the central observability system, so keep a system that tracks it.
Ease of Doing: ★★★★☆
Track metadata is a well-documented practice and can be done with ready-to-use tooling like AWS Glue DataBrew and Apache Atlas
Cost: ★★☆☆☆
The cost can be reasonable and mainly involves the engineer's time to set up and maintain the metadata management system
Impact: ★★★☆☆
Centralizing metadata management is impactful for identifying and tracking data sources to organize and push it in the right direction
Implement data integration middleware.
This is not as uncommon as you may think, with the possibility of observability systems streaming data through tooling like Kafka
Ease of Doing: ★★☆☆☆
Setting up and configuring middleware tools comes with a degree of complexity. It's a cakewalk for SREs who know Kafka, but those without this skill might need more time
Cost: ★★★☆☆
The cost is moderate as it involves engineer time
to learn Kafkafor setup and maintenance of middleware tooling, a lot of which doesn’t have vendor fees
Impact: ★★★★☆
This integration can have a high level of impact if you identify data flow issues due to disparate sources
Explore data federation models.
You could implement techniques that help you do real-time aggregation of data from various sources as needed
Ease of Doing: ★★☆☆☆
The concept of data federation models is not super complex, but it requires you to have some background with it to hit the ground running
Cost: ★★★★☆
You may need to invest in tools or technologies — like customized open source — that support data federation but it is a strategic investment if you end up needing to do it
Impact: ★★★★☆
Data federation models have a significant impact on aggregating real-time data from various sources
Wrapping up
This is kind of meta, but observability systems need their own observability — meta-observability! I mentioned monitoring several times to prevent or resolve data flow issues.
The solutions I’ve mentioned are just springboards for you to explore each area in more detail on your own. If you have any specific questions, feel free to ask.
It’s important that we address the challenges I’ve outlined. That’s what it will take to make observable data flow as smooth and pure as freshly melted butter.

Wow, great detail!!! When convenient, I'd love to see you do a deep dive on "the team aims to get open-source tooling rather than pay vendors from Day 1". In other words, I would enjoy hearing perspectives on open-source tooling (I guess both on-prem and cloud-hosted) vs commercial. The conventional wisdom is open source is just a vehicle for getting code developed, but commercial vendors add value on top both in terms of support, but also integration, ease of use, scale, etc. Would be great to see this subject dissected.